






Introduction
In Webflow, managing your robots.txt file is straightforward, but often overlooked. By default, Webflow auto-generates a basic robots.txt for your published site. But for those with more advanced SEO needs, or even just a desire to keep unnecessary pages out of Google’s index, customizing this file becomes one of the main priorities.
Whether you're building a simple portfolio or managing a large-scale content hub, knowing how to correctly use robots.txt in Webflow can help you:
- Control what search engines crawl
- Prevent indexing of thin or duplicate content
- Ensure private or staging pages stay private
Why does this matter? Because how your site gets crawled can directly impact how quickly (and accurately) your pages appear in search. A misconfigured robots.txt can unintentionally block important content, waste crawl budget, or leave sensitive pages exposed to search engines.
In this guide, we’ll cover everything from beginner steps to advanced strategies, tailored specifically for Webflow-hosted sites. If you ever need help beyond this tutorial, our SEO agency for tech startups can help you implement the right setup for your project.
What is robots.txt?
A robots.txt file is a plain text file that lives at the root of your website and tells search engine bots which parts of your site they can and cannot crawl. While it doesn’t directly impact rankings, it plays a crucial role in crawl efficiency, helping search engines prioritize the most valuable content.
Finding, Editing, and Testing Your robots.txt in Webflow (Beginner Steps)
Managing your robots.txt file in Webflow starts with understanding where to find it, how to modify it, and how to ensure it’s working as expected.
Step-by-Step Instructions:
Access Your SEO Settings:
Go to your Webflow Project Settings > SEO tab > Indexing section.
Locate the Robots.txt Field
Scroll to the robots.txt field. If it’s not visible, ensure you have a paid site plan and a connected custom domain.
Then continue adding your directives using standard syntax:
User-agent: *
Disallow: /private-page/
Allow: /This tells bots to avoid the /private-page/ but crawl everything else.

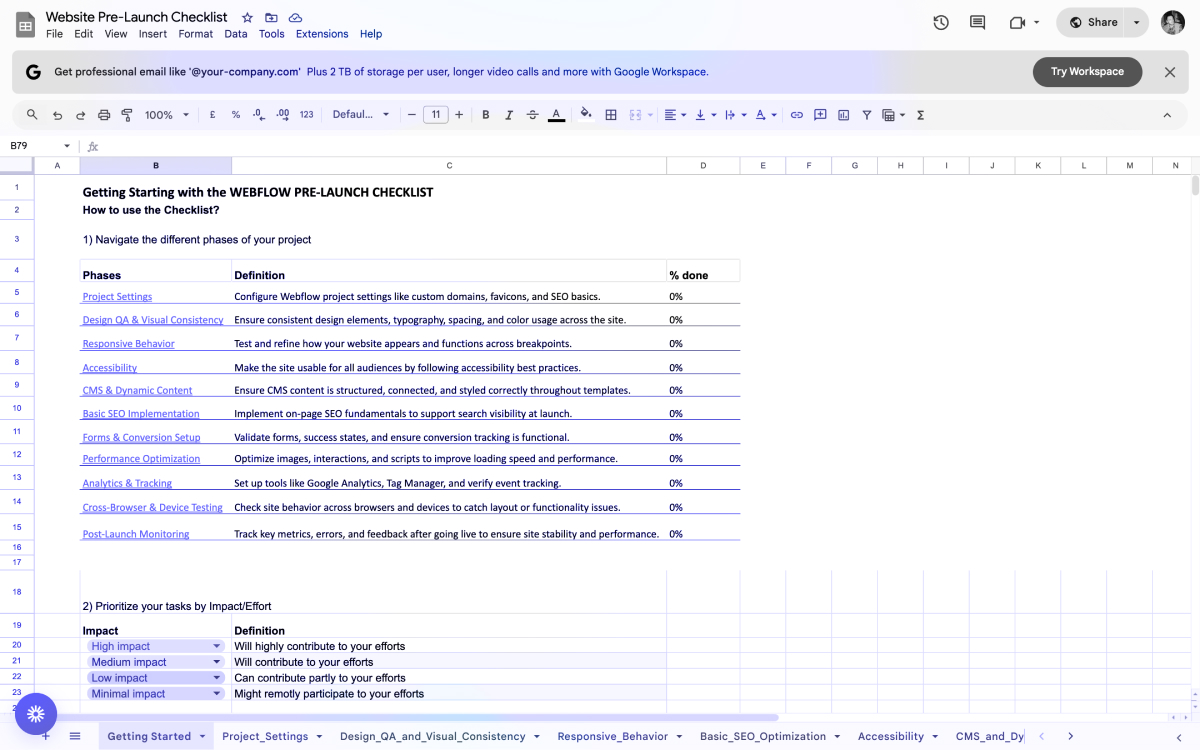
Launching soon? Don’t wing it.
Use our free website launch checklist to avoid common pitfalls—like broken links, tracking issues, and SEO mistakes. It’s a comprehensive pre- and post-launch guide built for teams that care about getting it right the first time.
Save and Publish
Click Save Changes, then Publish your site. Your robots.txt will now be live at https://yourdomain.com/robots.txt.
Test the File
You can test the file by following the instructions:
- Open your published robots.txt in a browser
- Use Google’s robots.txt Tester in Search Console to check for syntax errors or blocked URLs.
- Use Detailed SEO google chrome extension to test your robots.txt file
Notes for Beginners:
- Webflow requires a paid Site Plan for custom robots.txt usage.
- If you're using the webflow.io subdomain, toggle "Disable search engine indexing" in settings instead.
- Always republish your site after making changes.
Even for beginners, managing robots.txt in Webflow can be a low-effort, high-impact SEO move. Here's a video of Google staff giving a detailed robots.txt overview:
Advanced Use Cases & Troubleshooting (Technical SEO)
Beyond basic crawl instructions, robots.txt can be a strategic SEO tool, especially for Webflow users managing large content hubs, staging environments, or multilingual sites.
Here are a few advanced use cases:
Blocking Specific Crawlers
If you're seeing aggressive bot traffic (e.g. Ahrefs, Semrush), you can block them directly:
User-agent: AhrefsBot
Disallow: /Use this sparingly as blocking search engine bots like Googlebot or Bingbot can remove you from their index. You can find a list of most commonly used user agents in the article Yoast wrote on robots.txt.
Fine-Tuning CMS Page Crawling
Webflow doesn’t let you exclude individual CMS items from sitemaps. But with robots.txt, you can prevent crawl access:
User-agent: *
Disallow: /blog/placeholder-post/Combine this with page-level noindex meta tags for maximum control.
Managing Crawl Budget
If you're publishing lots of utility pages (thank-you pages, filters, internal tools), disallow those paths so Google focuses on what matters:
Disallow: /thank-you/
Disallow: /internal/Handling Multilingual or Multi-domain Sites
If you use hreflang or reverse proxies, you may want to:
- Add multiple Sitemap: entries manually
- Block region-specific subfolders
- Customize robots.txt for staging vs. production
Common Troubleshooting Tips:
- "robots.txt not found": Make sure you’re on a paid plan, the domain is connected, and the site is published.
- Rules not updating: Save your changes and re-publish. Some users report needing to trigger a full site publish.
- Resources blocked: Don’t block CSS, JS, or image folders—Google needs those to render your site.
Takeaway: robots.txt can do a lot, but it’s only one layer. Combine it with canonical tags, structured internal linking, and clean sitemaps for best results.
Best Practices: Dos and Don’ts for robots.txt in Webflow
Done right, robots.txt can be a helpful tool to fine-tune how your Webflow site is crawled. Done wrong, it can block your most important pages from ever getting indexed. Here’s how to stay on the right side of that line.
Dos for robots.txt:
Include your sitemap
Webflow adds this automatically, but if you’re using a custom Webflow sitemap, be sure to manually include it:
Sitemap: https://yourdomain.com/sitemap.xmlFor example, we optimized the robots.txt file for our crypto client Cryptoworth by manually inserting their sitemap link and tightening crawl rules. This ensured Google indexed only the right pages.
Tilipman Digital’s robots.txt tweaks made our site’s SEO much cleaner – our crawl errors dropped and search visibility improved.
— Ariel Eiberman, CMO @Cryptoworth

Use clear, intentional rules
Stick to clean, specific directives and avoid guesswork. Each group should begin with User-agent: followed by Allow: or Disallow: directives.
Test everything before and after publishing
Use Search Console’s robots.txt Tester and URL Inspection Tool to ensure your setup works as expected.
Use it to complement other SEO signals
Think of robots.txt as one part of the system. Use it alongside canonical tags, meta noindex rules, internal linking, and sitemaps for best results.
Don’ts for robots txt:
Block essential resources
Never disallow folders that contain JS, CSS, or images needed for rendering. Googlebot uses those to understand how your site appears to users.
Assume robots.txt hides private content
It only prevents bots from crawling, it doesn’t prevent indexing if the URL is linked elsewhere. Use noindex tags and password protection for sensitive pages.
Create conflicting or duplicate rules
Double-check for typos, overlapping paths, or contradictory entries (e.g. Allow and Disallow for the same path under the same user-agent).
Forget to publish
Webflow won’t apply your new robots.txt until you hit Publish. Saving is not enough.
By following these dos and don’ts, you’ll make sure your robots.txt file helps your visibility in search.
Common Issues and Fixes
Even when you follow best practices, things can still go sideways. Here are some of the most common robots.txt issues Webflow users run into, and how to fix them.
"robots.txt not found"
This usually happens when:
- Your site is still on the free webflow.io domain
- You haven’t enabled a Site Plan or connected a custom domain
- You haven’t published your site since editing robots.txt
Fix: Make sure your site is live on a custom domain with an active Site Plan, and then publish it.
"Blocked by robots.txt" error in Search Console
This means a page Google tried to crawl is explicitly disallowed.
Fix: Use the robots.txt Tester in Search Console to see which rule is blocking the page. Update or remove the rule if needed, republish, then request a re-crawl.
"Submitted URL blocked by robots.txt"
If you submit a sitemap that includes pages blocked by robots.txt, Search Console will flag this.
Fix: Either remove those URLs from your sitemap or update your robots.txt to allow crawling. When you change page URLs or remove pages, set up 301 redirects so visitors and search engines are automatically sent to the updated pages.
robots.txt won't update
If you’ve made changes but still see the old file at /robots.txt, it might be a caching issue or you forgot to publish.
Fix: Re-save the SEO settings and publish your site again. You can also try a hard refresh or test the file in incognito mode. If you encounter a redirect loop during crawling, follow our "Too Many Redirects" error guide to troubleshoot and resolve it.
Pages still showing in search despite being disallowed
Blocking a page in robots.txt stops crawling, but not indexing if Google already knows the URL.
Fix: Add a noindex tag to the page using Webflow’s page settings, and request removal in Search Console.
Not sure how to do that? We have written a guide outlining the Webflow Google Search Console integration.
By checking for these common issues regularly, you can avoid accidental visibility problems and keep your site crawl-friendly and SEO-healthy.
Common Questions and FAQs about robots.txt in Webflow
What does a robots.txt file contain?
A robots.txt file contains directives for search engine crawlers. Each group starts with a User-agent: line (e.g., * for all bots) and is followed by rules such as Disallow: or Allow:. Optionally, it can include a Sitemap: line to help bots discover all content.
Example:
User-agent: *
Disallow: /private-page/
Allow: /
Sitemap: https://example.com/sitemap.xmlDo I need a robots.txt file for SEO?
Not always, but it helps. While many smaller sites can go without it, having a well-structured robots.txt becomes more important as your site grows, especially when managing crawl budget, privacy, and multilingual content.
What happens if I don’t have a robots.txt file?
Nothing catastrophic. If no robots.txt exists, bots are allowed to crawl your entire site by default. It’s better to have one if you want to:
- Block non-essential or duplicate content
- Point crawlers to your sitemap
- Control indexing behavior on a site-wide level
Is robots.txt bad for SEO?
No. On its own, robots.txt is not bad for SEO, it’s a tool. And like with any other tools, problems arise only when it’s misconfigured. If you accidentally block important content (like your homepage or blog), then yes, it can hurt your visibility. But when used properly, it helps focus crawlers on the right content. To learn about more the tools you can use as part of Webflow SEO arsenal, read our article on debunking Webflow Misconceptions: Does Webflow Negatively Impact SEO?.
Why is robots.txt blocked?
If you see this message in Search Console, it usually means Googlebot was unable to fetch your robots.txt file. This could be due to:
- The file not being published (you forgot to hit "Publish")
- The site being hosted on the free webflow.io domain
- A temporary issue or server misconfiguration
How do I view my live robots.txt file in Webflow?
After publishing your site, go to https://yourdomain.com/robots.txt in any browser. If you’ve added custom rules in Project Settings → SEO → Indexing, they’ll appear there.
Can I use wildcards or pattern matching in robots.txt?
Yes. Robots.txt supports basic wildcard usage. For example:
Disallow: /tags/*This would block all URLs that begin with /tags/.
Does Webflow automatically include my sitemap in robots.txt?
Yes. Webflow auto-appends the Sitemap: directive linking to your sitemap.xml as long as you haven’t disabled auto-generation in settings.
Can I use robots.txt to remove a page from Google?
Not reliably. Blocking a page in robots.txt will stop crawling, but not indexing. If Google already knows about the URL, it might still appear in search. Use the noindex meta tag instead, or Webflow’s built-in "exclude from search" toggle on a per-page basis.
Can I block a specific CMS item using robots.txt?
Not directly through Webflow’s UI. However, you can disallow its URL path manually in robots.txt like:
Disallow: /blog/sample-post/To be thorough, also apply a noindex tag on the CMS item via the page settings.
Conclusion
Managing your robots.txt file in Webflow might seem like a small detail—but it plays a meaningful role in your site’s SEO strategy. Whether you're launching a simple landing page or scaling a content-heavy product site, a well-structured robots.txt ensures that search engines focus on the content that matters most.
From controlling crawl access to keeping private pages out of search results, and from refining crawl budget to improving indexation accuracy—robots.txt is your first line of defense (and direction) for how bots interact with your Webflow site.
If you’re unsure about how to implement this effectively across a growing or complex site, our Webflow development agency can help.
Now that you’ve got a full understanding of how robots.txt works in Webflow, you’re one step closer to a more performant, indexable, and search-ready website.
As a next step, consider the rise of AI-driven search, Webflow’s recent llms.txt update lets you guide AI models just as robots.txt guides traditional search engine bots.